 As part of PEBL 0.14,we offer a simple tool to help you combine data from multiple files into a single file.
As part of PEBL 0.14,we offer a simple tool to help you combine data from multiple files into a single file.Starting in 0.14, we use a data saving scheme and set of functions that help improve organization and prevent overwriting. Within each battery folder, a data\ folder is created. Within each data folder, a subject code folder is created, and one or more files saving data are created for each participant in that subfolder. For some experiments, a master pooled data file will also be created, but not for all.
For users of command-line shells like BASH (available by default in linux and OSX, and downloadable via wingw in windows) it is pretty easy to combine data files from a bunch of participants into a single file for later analysis. Suppose you have 100 subjects; you have 100 data files, and if the files are all in the same directory, using commands like cat, grep, file, sed, head, etc. make combining data trivial. Putting the data files in separate subdirectories complicates this a bit, but people without these skills resort to terrible practices like opening up each file, one by one, and copying it into a spreadsheet. The PEBL Data combining tool will make this a thing of the past! Embedded within this post is a video that gives a walkthrough of how to use it, but a written summary is below.
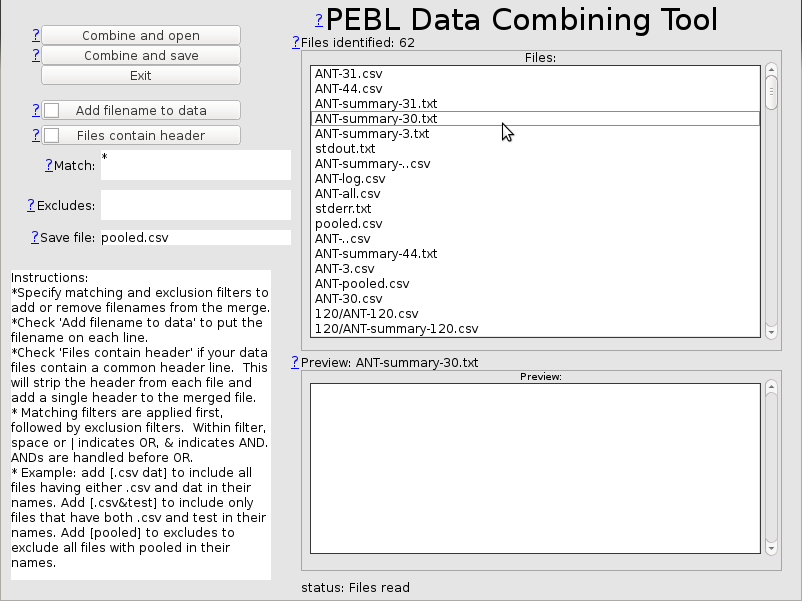
The combiner launches from the launcher, opening in whatever directory you are currently looking at. To begin with, the listbox on the right shows all folders (recursively in directories) that match the particular pattern, which, to begin with is *==everything.
This may include all the files you want, but it likely includes more than you want. You can select any file and get a preview in the lower right to be sure it is what you want.
When you have selected the files you want, be sure the save file is correct (default is 'pooled.csv'), and you are ready to merge. But first, you should figure out if the data have a header row. Typically, PEBL data will all have a header row indicating what each column means. If so, click the 'files contain header' box, and it will strip the header from each file, and add it once back into the pooled file.
The last thing to do is determine whether you want each line marked with the file it came from. This could be useful, especially if subject codes got distorted or lost.
When you are ready, you can click 'combine and open' to create the pooled file and open it with the default spreadsheet. Otherwise, you can just hit 'combine' and it will create that file.
A couple caveats. The combiner only works with text-based files, and so if you try to make it work with other types (xls, doc, etc), it probably won't work. Next, it doesn't check for whether the files have the same format, so you can easily create a garbage pooled file by not doing the pattern matching right. Finally, be careful you exclude the pooled.csv file from the match if you have created it already--this will essentially include every participant twice, and will distort your results.
As a result, you should have a .csv file that has one row for every observation, with each row marked by all of the conditions of interest (including participant code), allowing for proper handling for repeated measures. Typicially, you might want to aggregate these across participants, using a pivot table in a spreadsheet, or something like 'tapply' or 'aggregate' in R.
If you find this useful, let us know, and contribute to the PEBL crowdfunding campaign. I'd be interested in adding features to this, maybe to do some simple aggregation and variable selection to make data analysis even easier.
No comments:
Post a Comment